
Starrocks Insert into Files: A Comprehensive Guide
Are you looking to enhance your data ingestion process with Starrocks? If so, understanding how to use the “insert into files” command is crucial. This guide will delve into the intricacies of this command, providing you with a detailed, multi-dimensional introduction to help you master it.
Understanding the Basics

The “insert into files” command in Starrocks allows you to load data from various file formats into your database. This command is particularly useful when dealing with large datasets, as it enables you to efficiently import data from external sources.
Before diving into the specifics, it’s essential to understand the basic syntax of the “insert into files” command:
INSERT INTO TABLE table_nameSELECT FROM FILE 'path_to_file'[WHERE conditions];In this syntax, “table_name” refers to the target table where you want to insert the data, “path_to_file” is the location of the file you want to import, and “WHERE conditions” (optional) are any filtering criteria you wish to apply.
Supported File Formats
Starrocks supports a wide range of file formats, making it versatile for various data ingestion scenarios. Here’s a list of some commonly used file formats:
| File Format | Description |
|---|---|
| Parquet | Columnar storage format with rich data compression and encoding features. |
| ORC | Optimized Row Columnar storage format, which is efficient for both storage and query performance. |
| CSV | Comma-separated values format, widely used for data interchange. |
| JSON | JavaScript Object Notation format, suitable for semi-structured data. |
| Avro | Binary data serialization format, designed to be portable and self-describing. |
Performance Optimization
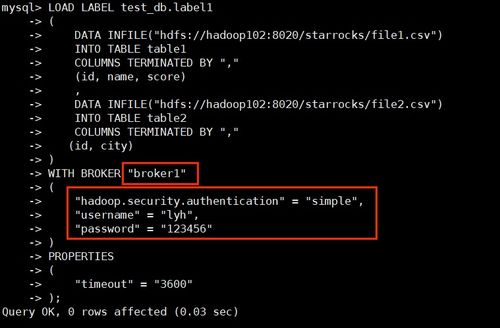
When using the “insert into files” command, it’s crucial to optimize your data ingestion process for better performance. Here are some tips to help you achieve this:
- Partitioning: Partition your data based on relevant keys to improve query performance and manage large datasets more efficiently.
- Sampling: Use sampling techniques to load a subset of your data for initial testing or to speed up the ingestion process.
- Compression: Utilize data compression to reduce storage requirements and improve query performance.
- Parallelism: Leverage parallel processing capabilities to speed up data ingestion.
Use Cases
The “insert into files” command in Starrocks is applicable in various scenarios. Here are some common use cases:
- ETL Processes: Use this command to load data from external sources into Starrocks for further analysis and reporting.
- Data Integration: Integrate data from different systems and sources into a unified Starrocks database for a comprehensive view.
- Real-time Analytics: Ingest real-time data into Starrocks for immediate analysis and decision-making.
- Batch Ingestion: Load large volumes of historical data into Starrocks for long-term storage and analysis.
Conclusion
Mastering the “insert into files” command in Starrocks is essential for efficient data ingestion and management. By understanding the basics, supported file formats, performance optimization techniques, and use cases, you can leverage this powerful command to enhance your data ingestion process and unlock the full potential of Starrocks.





