
Read CSV File Python: A Comprehensive Guide
Reading CSV files in Python is a fundamental skill for data analysis and manipulation. CSV, which stands for Comma-Separated Values, is a popular file format for storing tabular data. This guide will walk you through the process of reading a CSV file using Python, covering various aspects such as importing libraries, understanding the data, and handling different scenarios.
Importing Necessary Libraries

Before you can start reading a CSV file, you need to import the required libraries. The most commonly used library for this purpose is csv, which is part of Python’s standard library. Here’s how you can import it:
import csvAlternatively, you can use the pandas library, which provides a more comprehensive set of tools for data analysis. To use pandas, you need to install it first using pip:
pip install pandasReading a Simple CSV File
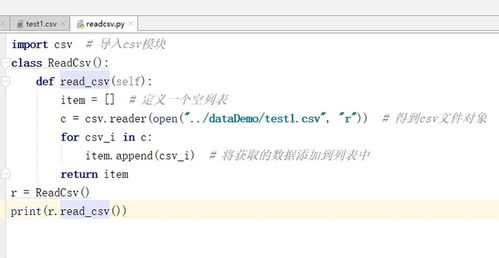
Let’s start with a simple example. Suppose you have a CSV file named data.csv with the following content:
name,age,cityAlice,25,New YorkBob,30,Los AngelesCharlie,35,ChicagoTo read this file using the csv library, you can use the following code:
with open('data.csv', 'r') as file: reader = csv.reader(file) for row in reader: print(row)This will output:
['name', 'age', 'city']['Alice', '25', 'New York']['Bob', '30', 'Los Angeles']['Charlie', '35', 'Chicago']The csv.reader object reads the file line by line, and the for loop iterates over each row.
Reading a CSV File with Pandas

Using pandas, reading a CSV file is even simpler. Here’s how you can do it:
import pandas as pddata = pd.read_csv('data.csv')print(data)This will output:
name age city0 Alice 25 New York1 Bob 30 Los Angeles2 Charlie 35 ChicagoPandas automatically converts the first row to column names, and the rest of the rows to data.
Handling Different CSV File Formats
CSV files can have different formats, such as tab-separated values (TSV) or space-separated values (SSV). You can specify the delimiter when reading a CSV file using the delimiter parameter:
import pandas as pddata = pd.read_csv('data.tsv', delimiter='t')print(data)Similarly, you can specify the delimiter as a space:
import pandas as pddata = pd.read_csv('data.ssv', delimiter=' ')print(data)Reading a Large CSV File
Reading a large CSV file can be memory-intensive. To handle this, you can use the chunksize parameter in pandas:
import pandas as pdchunk_size = 1000for chunk in pd.read_csv('large_data.csv', chunksize=chunk_size): Process the chunk print(chunk)This will read the file in chunks of 1000 rows, allowing you to process the data without consuming too much memory.
Reading a CSV File with Missing Values
CSV files can contain missing values, which are represented by empty strings or special characters like NaN. Pandas automatically handles missing values, but you can also specify the missing value marker using the na_values parameter:
import pandas as pddata = pd.read_csv('data.csv', na_values=['', 'NA', 'NaN'])print(data.isnull().sum())This will output the number of missing values in each column:
name 0age 0city 0dtype: int64Reading a CSV File with a Header Row
By default, pandas assumes the first row






