
Yarn Jar Example: A Detailed Guide to HDFS File Processing
Are you looking to delve into the world of Hadoop and Yarn? Do you want to understand how to process files using Yarn and the Hadoop Distributed File System (HDFS)? If so, you’ve come to the right place. In this article, I’ll walk you through the process of using a Yarn jar example to handle HDFS files. We’ll explore the necessary steps, the tools involved, and the best practices to ensure a smooth and efficient workflow.
Understanding Yarn and HDFS

Before we dive into the Yarn jar example, let’s take a moment to understand the two key components: Yarn and HDFS.
Yarn, or Yet Another Resource Negotiator, is a resource management platform for Hadoop. It allows you to efficiently manage and allocate resources across a Hadoop cluster. Yarn is responsible for scheduling tasks and managing the execution of applications on the cluster.
HDFS, on the other hand, is a distributed file system designed to store large data sets across multiple machines. It provides high throughput access to application data and is fault-tolerant, meaning it can recover from the failure of any single machine in the cluster.
Setting Up Your Environment
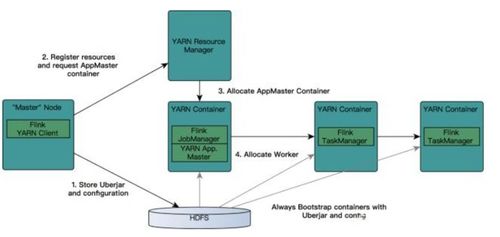
Before you can start processing files using Yarn, you need to set up your environment. Here’s a step-by-step guide to help you get started:
- Install Hadoop on your machine or set up a Hadoop cluster.
- Start the Hadoop services, including HDFS and Yarn.
- Set up your Java development environment.
- Download the Yarn jar example from the official Hadoop website or a trusted source.
Understanding the Yarn Jar Example
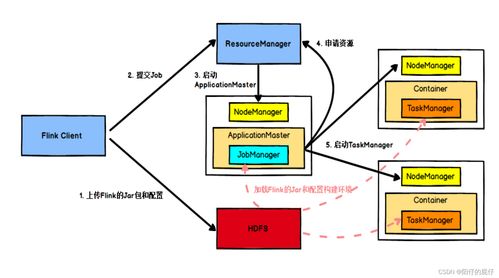
The Yarn jar example is a simple Java program that demonstrates how to submit a job to Yarn and process files stored in HDFS. Let’s take a closer look at the components of this example:
| Component | Description |
|---|---|
| Main Class | The entry point of the program, which initializes the job and submits it to Yarn. |
| Mapper | Performs the initial processing of the input files. It reads the input data, performs some transformations, and emits intermediate key-value pairs. |
| Reducer | Aggregates the intermediate key-value pairs produced by the mapper and generates the final output. |
| Input Format | Specifies how the input data is read from HDFS. In this example, it’s a simple text file input format. |
| Output Format | Specifies how the output data is written to HDFS. In this example, it’s a text file output format. |
Running the Yarn Jar Example
Once you have the Yarn jar example set up, you can run it using the following command:
hadoop jar yarn-example.jarThis command submits the job to Yarn, which then schedules and executes it on the cluster. The output will be written to the specified output directory in HDFS.
Monitoring and Troubleshooting
While your job is running, you can monitor its progress using the Yarn web interface. This interface provides detailed information about the job, including the number of tasks completed, the execution time, and any errors that may have occurred.
In case you encounter any issues, here are some common troubleshooting steps:
- Check the Yarn logs for any error messages.
- Ensure that the input and output directories exist in HDFS.
- Verify that the Hadoop services are running correctly.
- Check the network connectivity between your machine and the Hadoop cluster.




