
Loading CSV File into DataFrame in Python Jupyter: A Detailed Guide
Working with CSV files is a common task in data analysis, and Python, with its powerful libraries like pandas, makes it incredibly easy to load and manipulate these files. In this guide, I’ll walk you through the process of loading a CSV file into a DataFrame in Jupyter Notebook, providing you with a comprehensive understanding of each step involved.
Loading the CSV File

Before you can load a CSV file into a DataFrame, you need to have it available. Let’s assume you have a CSV file named “data.csv” in the same directory as your Jupyter Notebook. To load the file, you’ll use the pandas library’s `read_csv` function.
import pandas as pddf = pd.read_csv('data.csv')This line of code imports the pandas library and reads the “data.csv” file into a DataFrame named “df”. The DataFrame will contain all the data from the CSV file, including the headers.
Understanding the DataFrame
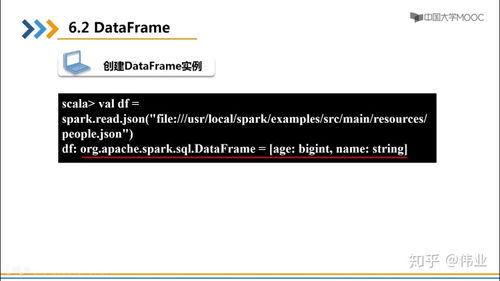
Once you’ve loaded the CSV file into a DataFrame, it’s important to understand its structure. You can use the `head()` function to display the first few rows of the DataFrame, which will give you an idea of the data you’re working with.
df.head()This will output the first five rows of the DataFrame, including the headers. You can also use the `info()` function to get a summary of the DataFrame, including the number of non-null values, the data type of each column, and the memory usage.
df.info()Exploring the Data
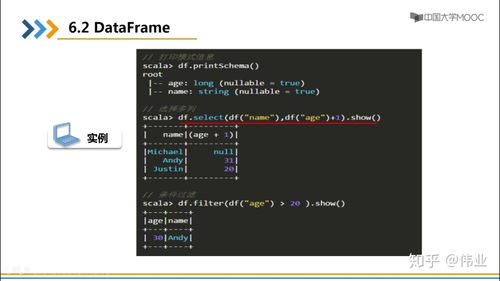
Now that you have a basic understanding of the DataFrame, you can start exploring the data. You can use the `describe()` function to get a statistical summary of the data, including the mean, median, standard deviation, and more.
df.describe()This will output a table with the statistical summary of the data. You can also use the `value_counts()` function to get the frequency distribution of a particular column.
df['column_name'].value_counts()Filtering and Sorting the Data
One of the most powerful features of pandas is its ability to filter and sort data. You can use boolean indexing to filter rows based on certain conditions. For example, to filter the DataFrame for rows where the “column_name” is greater than 10, you can use the following code:
filtered_df = df[df['column_name'] > 10]This will create a new DataFrame named “filtered_df” that contains only the rows where the “column_name” is greater than 10. You can also sort the data using the `sort_values()` function.
sorted_df = df.sort_values(by='column_name', ascending=False)Grouping and Aggregating the Data
Grouping and aggregating data is another common task in data analysis. You can use the `groupby()` function to group the data by one or more columns, and then apply an aggregation function to each group. For example, to calculate the mean of the “column_name” for each group, you can use the following code:
grouped_df = df.groupby('group_column').agg({'column_name': 'mean'})This will create a new DataFrame named “grouped_df” that contains the mean of the “column_name” for each group.
Exporting the DataFrame to a CSV File
After you’ve finished working with the DataFrame, you may want to export it back to a CSV file. You can use the `to_csv()` function to do this. For example, to export the DataFrame to a file named “output.csv”, you can use the following code:
df.to_csv('output.csv', index=False)This will create a new CSV file named “output.csv” in the same directory as your Jupyter Notebook. The `index=False` parameter is used to prevent pandas from including the row index in the CSV file.
By following these steps, you should now have a solid understanding of how to load a CSV file into a DataFrame in Python Jupyter. Whether you’re a beginner or an experienced data analyst, this guide should provide you with the knowledge you need to effectively work with CSV files in your data analysis projects.




