
Hadoop Distributed File System: A Comprehensive Guide
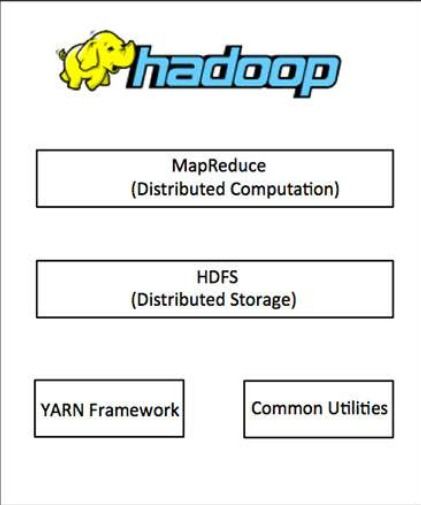
The Hadoop Distributed File System (HDFS) is a crucial component of the Hadoop ecosystem, designed to store large datasets across multiple machines. In this article, we will delve into the intricacies of HDFS, exploring its architecture, features, and use cases. By the end, you’ll have a comprehensive understanding of how HDFS functions and its significance in big data processing.
Understanding HDFS Architecture

HDFS is designed to handle large-scale data storage and processing, making it an essential tool for big data applications. Its architecture is based on a master-slave model, where the NameNode acts as the master and the DataNodes act as the slaves.
| Component | Description |
|---|---|
| NameNode | Manages the file system namespace and regulates access to files by clients. |
| DataNode | Stores data and performs data block management. |
The NameNode maintains metadata about the file system, such as the file structure and the location of data blocks. The DataNodes, on the other hand, store the actual data blocks and report their status to the NameNode.
Features of HDFS

HDFS offers several features that make it an ideal choice for big data storage and processing. Let’s explore some of these features:
- High Throughput: HDFS is designed to handle large-scale data processing with high throughput, making it suitable for big data applications.
- Scalability: HDFS can scale up to petabytes of storage and thousands of nodes, making it an excellent choice for large-scale data storage.
- High Availability: HDFS supports high availability by replicating data blocks across multiple nodes, ensuring data durability and fault tolerance.
- Read-Write Access: HDFS provides both read and write access to data, making it suitable for various data processing tasks.
- Low Latency: HDFS is optimized for low-latency access to data, making it an ideal choice for real-time applications.
Use Cases of HDFS
HDFS is widely used in various industries for big data storage and processing. Here are some common use cases:
- Web Search: HDFS is used to store and process large volumes of web data, enabling search engines to index and retrieve relevant information.
- Machine Learning: HDFS is used to store and process large datasets for machine learning applications, such as natural language processing and image recognition.
- Financial Services: HDFS is used to store and process financial data, enabling institutions to analyze market trends and make informed decisions.
- Healthcare: HDFS is used to store and process medical data, enabling healthcare providers to analyze patient records and improve patient care.
Performance Optimization in HDFS
Optimizing HDFS performance is crucial for efficient big data processing. Here are some tips to enhance HDFS performance:
- Proper Configuration: Configure HDFS parameters, such as block size, replication factor, and memory settings, to optimize performance.
- Data Locality: Ensure that data is stored on nodes that are geographically close to the processing nodes to minimize data transfer time.
- Network Optimization: Optimize network settings, such as bandwidth and latency, to improve data transfer rates.
- Hardware Upgrades: Upgrade hardware components, such as storage and memory, to enhance HDFS performance.
Conclusion
Hadoop Distributed File System (HDFS) is a powerful tool for big data storage and processing. Its robust architecture, features, and use cases make it an essential component of the Hadoop ecosystem. By understanding the intricacies of HDFS, you can leverage its capabilities to process large datasets efficiently and effectively.





