
Fine-Tuning Gemini with PDF Files: A Comprehensive Guide
Are you looking to enhance your Gemini model with PDF files? If so, you’ve come to the right place. In this detailed guide, we’ll explore the process of fine-tuning Gemini with PDF files from multiple dimensions. Whether you’re a beginner or an experienced user, this article will provide you with the knowledge and tools you need to get started.
Understanding Gemini

Gemini is a powerful language model developed by Hugging Face. It is designed to generate human-like text and can be fine-tuned for various tasks, including summarization, translation, and question-answering. Gemini is based on the Transformer architecture and has been pre-trained on a large corpus of text data.
Why Fine-Tune Gemini with PDF Files?
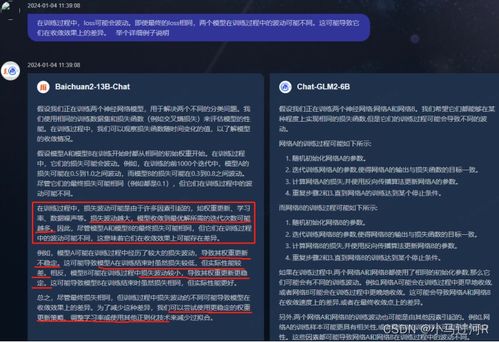
Fine-tuning Gemini with PDF files can be beneficial for several reasons:
-
Improved domain-specific knowledge: PDF files often contain domain-specific information that can be valuable for your application.
-
Enhanced performance: Fine-tuning can help improve the performance of Gemini on specific tasks, such as summarization or question-answering.
-
Customization: Fine-tuning allows you to customize Gemini for your specific needs, such as focusing on a particular domain or language.
Preparation
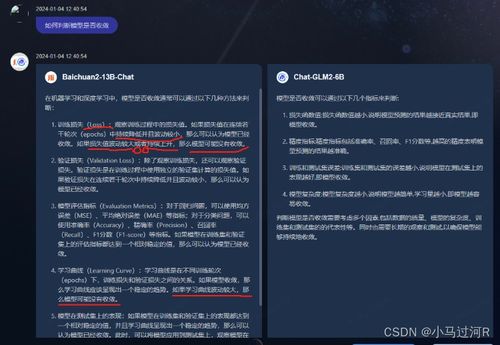
Before you begin fine-tuning Gemini with PDF files, you’ll need to prepare the following:
-
PDF files: Collect a diverse set of PDF files relevant to your domain.
-
Text data: Convert the PDF files into text data, ensuring that the text is clean and well-formatted.
-
Pre-trained Gemini model: Download a pre-trained Gemini model from Hugging Face’s Model Hub.
-
Training environment: Set up a suitable training environment with the necessary libraries and dependencies.
Converting PDF Files to Text
Converting PDF files to text is an essential step in the process. There are several tools and libraries available to help you with this task:
-
PyPDF2: A Python library for reading PDF files.
-
PDFMiner: A Python library for extracting information from PDF files.
-
PDF.js: A JavaScript library for rendering and manipulating PDF files.
Here’s an example of how to convert a PDF file to text using PyPDF2:
import PyPDF2def pdf_to_text(pdf_path): with open(pdf_path, 'rb') as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) text = "" for page_num in range(pdf_reader.numPages): page = pdf_reader.getPage(page_num) text += page.extractText() return textpdf_path = "example.pdf"text = pdf_to_text(pdf_path)print(text)Fine-Tuning Gemini
Once you have your text data and pre-trained Gemini model, you can proceed with fine-tuning. Here’s a step-by-step guide:
-
Load the pre-trained Gemini model and tokenizer.
-
Prepare your text data for training.
-
Define your training parameters, such as the learning rate, batch size, and number of epochs.
-
Train the model using your text data.
-
Evaluate the model’s performance on a validation set.
-
Save the fine-tuned model for future use.
Here’s an example of how to fine-tune Gemini using the Hugging Face Transformers library:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, Seq2SeqTrainer, Seq2SeqTrainingArgumentsmodel_name = "google/gemini"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSeq2SeqLM.from_pretrained(model_name)train_args = Seq2SeqTrainingArguments( output_dir="./results", evaluation_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, per_device_eval_batch_size=16, weight_decay=0.01, save



