
Distributed File System: A Comprehensive Guide
A distributed file system is a crucial component in modern computing environments, enabling the storage and retrieval of data across multiple machines. In this article, we will delve into the intricacies of distributed file systems, exploring their architecture, benefits, challenges, and real-world applications.
Understanding Distributed File Systems

Before we dive into the details, let’s clarify what a distributed file system is. Unlike traditional file systems that store data on a single machine, a distributed file system spans multiple machines, allowing for greater scalability, fault tolerance, and performance.
Architecture of Distributed File Systems
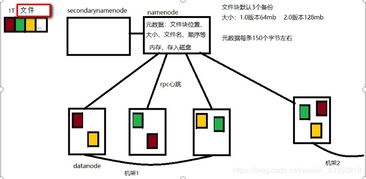
The architecture of a distributed file system is designed to ensure efficient data storage, retrieval, and management. Here are some key components:
- Client-Server Model: The distributed file system follows a client-server model, where clients request data from servers. The server manages the storage and retrieval of data, while the client handles the user interface and application logic.
- Metadata Server: The metadata server stores information about the files, such as their location, size, and permissions. This information is crucial for efficient data retrieval and management.
- Data Nodes: Data nodes are responsible for storing and managing the actual data. They communicate with the metadata server to determine where to store and retrieve data.
- Replication: To ensure fault tolerance, data is often replicated across multiple data nodes. This redundancy minimizes the risk of data loss in case of hardware failures.
Benefits of Distributed File Systems
Distributed file systems offer several advantages over traditional file systems:
- Scalability: Distributed file systems can easily scale to accommodate growing data storage needs. By adding more data nodes, the system can handle larger datasets and increased user load.
- Fault Tolerance: With data replication and redundancy, distributed file systems can withstand hardware failures without losing data. This ensures high availability and reliability.
- Performance: By distributing data across multiple machines, distributed file systems can provide faster data access and improved performance, especially for large-scale applications.
- Cost-Effective: Distributed file systems can leverage commodity hardware, reducing the cost of storage infrastructure.
Challenges of Distributed File Systems
While distributed file systems offer numerous benefits, they also come with their own set of challenges:
- Complexity: Managing a distributed file system can be complex, requiring specialized knowledge and tools.
- Consistency: Ensuring data consistency across multiple nodes can be challenging, especially in the presence of concurrent access and updates.
- Network Latency: Distributed file systems rely on network communication, which can introduce latency and impact performance.
Real-World Applications
Distributed file systems are widely used in various industries and applications:
- Cloud Storage: Cloud providers like Amazon S3 and Google Cloud Storage use distributed file systems to store and manage vast amounts of data.
- Big Data Analytics: Distributed file systems like Hadoop’s HDFS are essential for processing and analyzing large datasets in big data applications.
- High-Performance Computing: Distributed file systems enable efficient data storage and retrieval in high-performance computing environments.
Comparison of Popular Distributed File Systems
Several distributed file systems have gained popularity over the years. Here’s a comparison of some of the most widely used ones:






